UnPuzzled
What is UnPuzzled ?
It is a jigsaw puzzle solver using AI
An overview
This project consists of two components : creation and solving of puzzles and checking adjacency of puzzle pieces.
I construct a puzzle generator, which takes a given image and cuts it up into a rectangular grid of uniform square puzzle pieces with each puzzle piece being of a specified dimension. It further randomly rotates each square piece by 0/90/180/270 degrees counterclockwise and shuffles up the pieces, thus creating a puzzle.
I construct several models (machine-learning based and non-machine learning based) which are trained to detect if two given puzzle pieces are adjacent or not. I create custom datasets for these models using a puzzle-pieces-pair generator which is similar to the puzzle generator mentioned above. The actual images to construct the custom datasets are taken from the CUB-200 dataset. From the start, I split the images in the CUB-200 dataset into training, validation and test portions. I construct custom validation and test datasets to validate and evaluate the checking-adjacency models.
I design a search algorithm which takes a puzzle board with the top-left corner filled in, searches for the best pieces to fit into the board till the board is filled completely. The task of determining which pieces fit better makes use of the checking-adjacency models. I create solvers, which integrate the models with the search algorithm. Finally, I evaluate and compare the performances of the solvers on a test-data set of puzzles which are constructed by the puzzle generator from the test-portion of the CUB-200 dataset split.
Unpuzzling
Here’s an animation of the solver in action
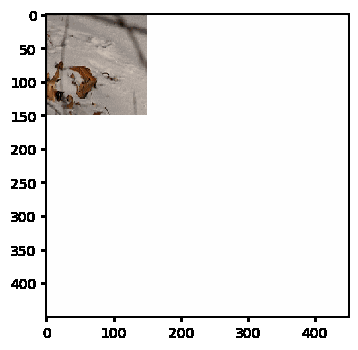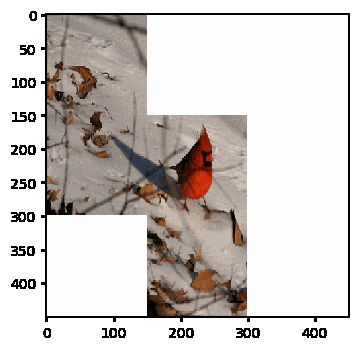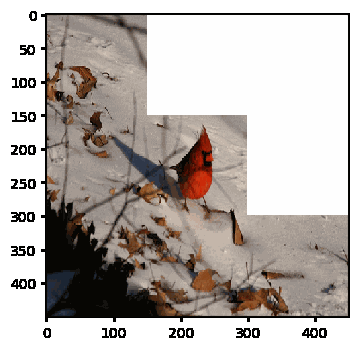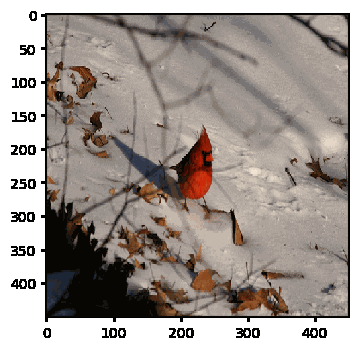
GitHub repository
The code for this project can be found at https://github.com/nivbhaskhar/UnPuzzled
Additionally, the code to deploy a Gradio based web application on Heroku, which simulates the puzzle-solving by the solver, can also be found in the same repository.
Results
I evaluated solvers based on three checking-adjacency models, namely AdjacencyClassifier_NoML (a hand-engineered model), FromScratch (a simple CNN) and ResNetFT (a fine-tuned ResNet 18 model).
There were 67 six-by-six puzzles, 11 five-by-five puzzles and 2 four-by-four puzzles in the evaluation set
| puzzle_sizes | no_of_puzzles | |
|---|---|---|
| 0 | 36 | 67 |
| 1 | 25 | 11 |
| 2 | 16 | 2 |
Both the AdjacencyClassifier_NoML and the ResNetFT solved 87.5 % of the puzzles completely correctly. FromScratch underperformed by solving only 37.5 % of the puzzles completely correctly.
| AdjacencyClassifier_NoML | FromScratch | ResNetFT | |
|---|---|---|---|
| avg_time_taken (sec) | 11.2126 | 18.9795 | 23.0482 |
| percentage_solved | 0.875 | 0.375 | 0.875 |
| avg_puzzle_sizes | 33.9875 | 33.9875 | 33.9875 |
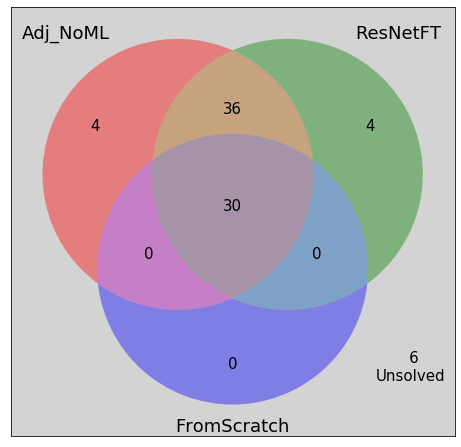
A venn diagram to visualize the comparisons
Comments
I further visually investigated what the models did on puzzles they did not solve completely correctly. It turned out that the solvers were putting together several chunks of the puzzles correctly even if they were not placing the pieces in the correct positions in the puzzle board. Further, the solvers sometimes put back mostly correct but rotated versions of the images. The current evaluation classified all these puzzles as unsolved.
If there are several similar pieces, and a solver chose and fit an incorrect piece, the puzzle of course will not be completely correctly solved. However the solver might (and did often) recover and get local chunks of the puzzle right. Perhaps a non-binary evaluation metric would aid in gauging the efficacy of these puzzle-solvers.